Introduction
Relevant lectures: 3.1T, 3.1F
This introduction defines multimedia, multimedia analysis, and machine learning, concepts which are central to TI2716-C.
Multimedia Analysis (MMA)
Multimedia content combines several “forms” of content such as text, audio, images, animation, video, and interactive content.
Multimedia analysis is a type of data science: where data science extracts knowledge from data, multimedia analysis extracts knowledge from multimedia data.
- It takes a top-down perspective that looks first at the required inputs and outputs of the system, and chooses what techniques to use accordingly. (This is in contrast with the bottom-up perspective of the TI2716-A Signal Processing and TI2716-B Image Processing courses.)
- It involves a certain amount of uncertainty: no (multimedia) representation of the real world reflects it perfectly, which we must account for.
Multimedia analysis often has to deal with the semantic gap between data and users. The semantic gap is defined depending on the available data and techniques, and the user’s information need. Often, problem formulations fail to really articulate this information need, in which case the system may be unable to successfully bridge the semantic gap.
Machine Learning (ML)
Machine learning is the science of getting computers to act without being explicitly programmed (Andrew Ng).
- “Learning” means defining a mathematical model of the input that can be used to make predictions.
- A system has “learned” if it can make (to some degree accurate) predictions about data it has not seen before.
There are three broad categories of machine learning (Wikipedia):
- Supervised learning: The system gets example input and output (“labels”), and has to figure out the rules that map inputs to outputs.
- Unsupervised learning: The system only gets example input, and has to figure out the structure in the input.
- Reinforcement learning: The system interacts with a dynamic environment where it has some goal (e.g. “safely drive from A to B”), and constantly gets feedback from its interaction with the environment.
Supervised and unsupervised learning are both relevant to TI2716-C, whereas reinforcement learning is out of the course’s scope.
Types of Tasks in MMA and ML
We encounter several types of tasks in multimedia analysis and machine learning, such as information filtering and retrieval, segmentation, clustering, ranking, classification, regression, and sequence recognition. Many of these are relevant to TI2716-C, and are covered in more detail below.
Information Filtering and Retrieval
Some people group information retrieval (IR) and information filtering (IF), but they have some distinctions:
| IR/IF | Input | Input characteristic | Collection |
|---|---|---|---|
| Information filtering | Profile | Changes infrequently and slowly | Relatively dynamic |
| Information retrieval | Query | Changes often and quickly | Relatively static |
Information Filtering
An information filtering system selects a subset of items to show to the user: its goal is to increase the “signal-to-noise” ratio. To do this, the system compares the user’s profile some reference characteristics (Wikipedia).
Information filtering is covered in the following chapters:
Information Retrieval
An information retrieval system is used to obtain multimedia resources relevant to an information need from a collection of multimedia data (Wikipedia).
Information retrieval is covered in the following chapters:
- Information Retrieval
- IR Using the Vector Space Model
- IR Using the Unigram Language Model
- Multimedia Information Retrieval
- Music Information Retrieval
Segmentation
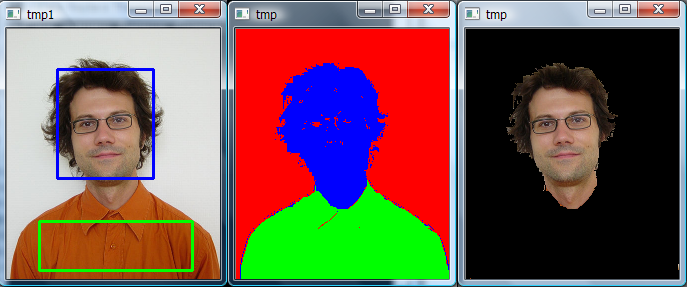
Segmentation is an unsupervised technique that assigns similar regions of content to “segments”. Examples include:
-
Image segmentation, where we split an image into segments that could be individual items (see image), background vs. foreground, or different parts of a human body, for example.

- Text segmentation, where we split some text into meaningful segments such as words, sentences, or topics.
- Speech segmentation, where we split audio up into individual phones, syllables or words.
{kind=link}
{kind=link}
(Image source: MathWorks)
Clustering
Clustering is an unsupervised technique that assigns similar items into groups based on some similarity measure. These items are usually represented as n-dimensional vectors of numbers.

(Image source: Politecnico Milano)
Ranking
Ranking is an unsupervised technique (classically) that produces a list of items ordered (high to low) by their similarity to a test item. This relevance is calculated using similarity measures between the test item and the items in the collection.
Classification
Classification is a supervised technique (classically) that takes a data point as input, and assigns it a class label as output. I like to think of classification as answering the question: “To which cluster does this (new) data point belong?”
A perceptron is a single-layer neural network that acts as a classifier.
Classification is covered in the following chapters:
Regression
Regression is a supervised technique to relate variables to each other. It is out of scope for TI2716-C.
Sequence Recognition
Sequence recognition is a supervised technique (classically) that performs simultaneous segmentation and classification. It could, for example, take spoken audio as input and produce a list of spoken words as output.
Sequence recognition is covered in the following chapters:
[ Home ]